How should LLMs change software architecture?
One of my favorite thinkers on programming is Casey Muratori, a low-level programmer, educator, and occasional Youtuber. In “The Only Unbreakable Law”, he makes the argument that, inevitably, the structure of software reflects the structure of the organizations that produce it. For example, Microsoft Windows has five separate volume control widgets, not due to any design reason, but due to the organizational structure of the teams that worked on the operating system.
More generally, the structure of our software reflects how we, as humans, understand the world and collaborate to project that understanding in to code. Practices and patterns such as object-orientation, clean code, containerization, and microservice architectures exist not due to something inherent about computers, but due to our human limitations and the need to overcome them. All of these practices, Muratori argues, restrict our ability to optimize our programs by cutting off options in their design space. From a performance perspective, these practices are bad, only necessary because we, as humans, need them in order to manage complexity and to work together.
A direct implication of this argument is that if we change, so should our code. As many have argued, AI technologies such as large language models act as extensions to our brains; they change how we think and how we work. So how should the object of our work—computer software—change as a result?
Coding assistants are a fundamental change to programming
How we produce software has changed dramatically since the release of GitHub Copilot in 2021 and the rise of AI-enabled tools such as Cursor, Windsurf, and Devin. The first programming language I spent serious time with when I was growing up in the 90s was Borland Turbo Pascal. Its IDE looked like this:
 .
Image source: Exploring Borland Turbo Pascal for DOS by Psycho Cod3r
.
Image source: Exploring Borland Turbo Pascal for DOS by Psycho Cod3r
Developing a Pascal program in Borland’s IDE in the 90s had a remarkably similar workflow to developing in Visual Studio Code in the 2020, thirty years later. You write some code in the editor, can set breakpoints, run and debug your program, evaluate expressions, see output, and edit accordingly. There are of course differences: in 2020 we had code-completion through language server protocols, linting, far more robust automated testing, sophisticated version control systems, and package managers. But the central loop of write, test, revise, remained intact. Copilot and its competitors have changed this.
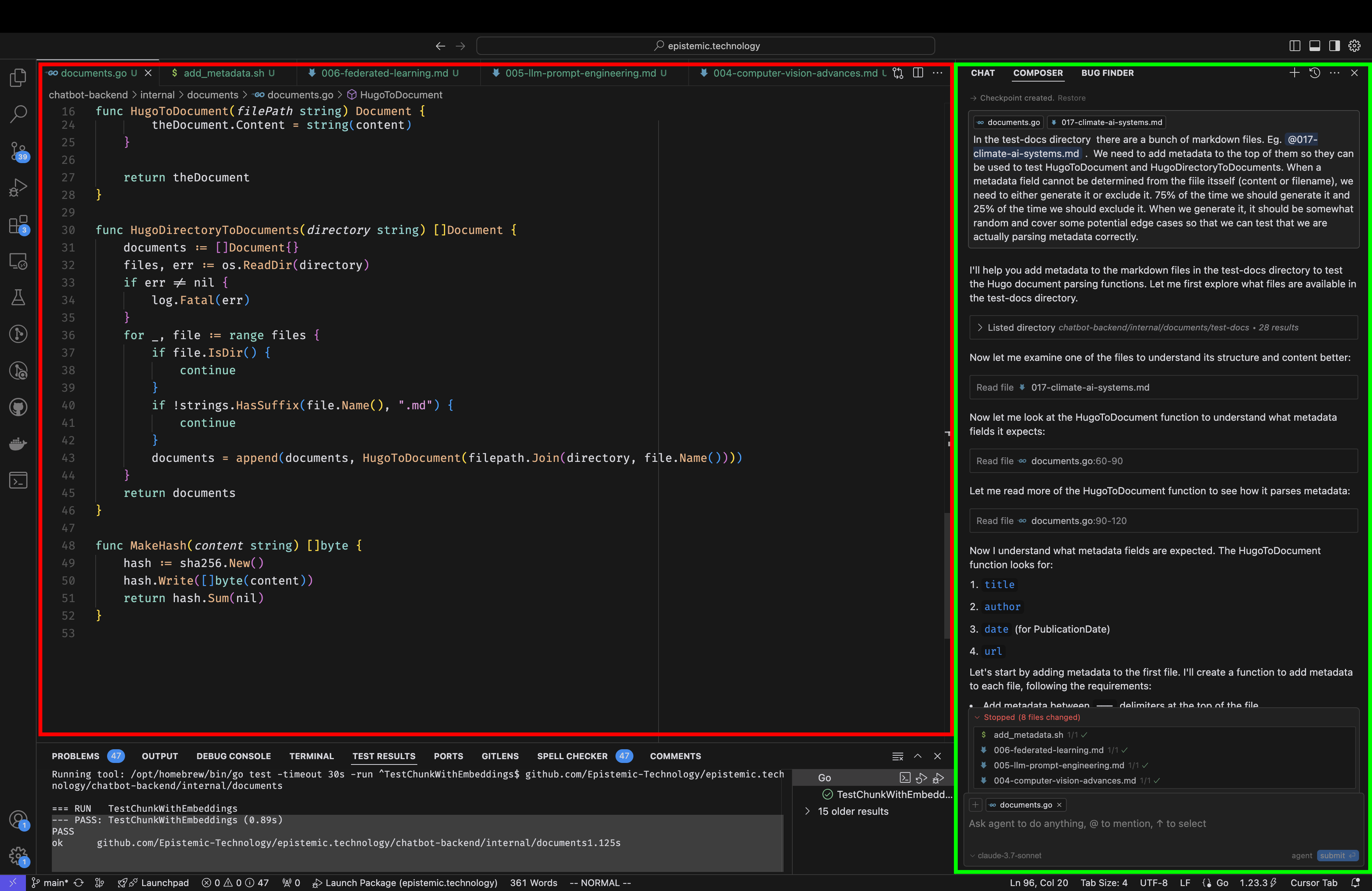
These tools, combined with large language models such as GPT or Claude, have shifted the focus of programmers’ attention, for perhaps the first time in the history of the practice, away from the main editor (highlighted in red). Instead, many of us spend much or most of our time in the green area, called the “AI Pane” in Cursor. We give instructions to our “AI Assistant” and it performs edits that are reflected in the editor. We review those, make adjustments, test, and give it further direction.
How AI could change software
This brings me to the central question of this post. Given that software architecture reflects not something inherent in computers but rather something about the humans that produce software, and given that the way we produce software is changing so dramatically, how should what we are producing change?
Plenty of people have argued for how AI is changing the process of software development, especially with the rise of “agentic” systems that have the ability to implement larger features that span multiple parts of a codebase and to take actions such as making pull requests, running shell scripts, or searching documentation. But what I am interested in is how that change in process should cause a corresponding change in product.
Recently, researchers at Princeton and the Indian Institute of Technology developed prototype wireless chips using AI. Not only did they find that they were able to generate designs far faster than with traditional techniques, but also the resulting chips often performed better. Most interestingly, the circuit designs are highly “unusual”—not something that any human would design.
 Image Source: AI slashes cost and time for chip design, but that is not all by John Sullivan, 2025
Image Source: AI slashes cost and time for chip design, but that is not all by John Sullivan, 2025
This example illustrates one of Muratori’s central arguments: freed from human constraints, the AI was able to more fully explore design space and find more efficient solutions than any human could have. However, the AI used in this system had an advantage that LLMs like GPT and Claude lack today: the ability to train against an “objective” metric of success. The researchers used industry-standard electromagnetic field simulation software to test designs produced by the system and to iterate their model based on its performance before finally producing physical prototypes for real-world validation. This is similar to the process that Deepmind used to train its early models to beat games like Breakout. As with training models to play games, the researchers could “score” the performance of the model-produced designs and use those scores for training. LLMs have no such objective standard. Instead, they train on human-generated text; they are prediction engines, predicting what a (perhaps talented) human would produce in a similar situation.
LLM-powered coding tools are very impressive, but have this fundamental limitation. Their training is limited by available data, mostly just text scraped from the Web. As a result, in my experience, even cutting-edge models are easily confused and perform badly at complex tasks. In the future, we might see machine-written software that is highly optimized and beyond human understanding, but today when LLMs produce code we cannot understand it is usually because it’s just bad. So the challenge is, how do we harness the power of LLMs while managing their shortcomings, and in particular, how do we structure software to facilitate that? I have a couple of ideas.
First, LLMs can allow us to reduce dependencies. Modern package managers such as npm, cargo, or go modules have made it easy to import others’ code into our own projects. This can increase development speed as it saves us from re-implementing the feature ourselves, but it often comes at the cost of increased maintenance (and possibly security) issues down-the-road. Dependencies can be large, like the React library, or small like the popular JavaScript package is-number, which simply checks if a value is a number (it’s harder than you might think). Libraries like React are great for large projects with complex user interfaces, but are overkill for many sites which just need to add some interactivity to otherwise static sites. And small packages like is-number can save us from having to think through potentially tricky edge cases for what should be a simple problem. In either case, LLMs can change the calculation of whether to add a dependency because they make it far faster to write routine code. You can prompt Claude or GPT to validate a number or process a form in vanilla JavaScript and it’s going to work quite well. I’m not saying that LLMs mean we never need to reach for external dependencies, but they push out the complexity frontier at which it makes sense for us to do so.
Second, LLMs encourage us to modularize our software. By this I mean creating boundaries in our software, whether those are between separate services or separate packages or something else. These boundaries have well-defined interfaces that we understand and that a single agent cannot cross. This practice goes in the opposite direction of the AI-designed chips, and therefore makes some potential optimizations of our code impossible. But in return, it creates an environment where LLMs are much more likely to succeed because the code is less complex and the constraints better defined. It also makes it easier for us to understand and evaluate what they produce. A significant tradeoff with LLM-produced code is that when you have to fix or otherwise modify it, it is like you are entering someone else’s codebase. You didn’t write the code, and so you need to invest time and energy into understanding it before you can improve it. The more you can delimit the space in which LLMs can make modifications, the easier it will be for you to exercise your own agency.
Many of the loudest voices on the effect of AI on software development are polarized in to two camps: those who claim that AI is somehow ruining software by producing buggy, insecure, and intellectual-property-violating code, and those who claim that modern AI tools will soon replace humans entirely. Reality, as is often the case, lies somewhere in the middle. Our software development practices are undergoing radical changes, but those changes bring new challenges. We need to adapt how we think about our product and practice accordingly. AI-based tools are not just drop-in replacements for human engineers, whether they be entry-, mid- or senior-level. Instead, they represent a qualitative change in software development that we need to grapple with seriously. We—and I—are still figuring out the implications of that, and they will surely change with the changing abilities of AI assistants, but that does not reduce the need to grapple with these questions today.
Sign up to receive posts directly to your email, or follow our RSS feed.